![]()
C 標準ライブラリ関数には標準出力に文字列を出力する printf 関数があります。これをワイドキャラクタ (≒Unicode) 出力に対応させたバージョンが wprintf 関数です。
ところが、 Windows の wprintf 関数は Unicode を出力できないというのです。にわかには信じられない話です。本当にそんなことがあるんでしょうか?
wprintf 関数の問題点と、 Windows のコンソールに Unicode を出力する方法を解説します。
はじめに、 引数に指定した文字列を標準出力に出力する簡単なサンプルプログラムを作成します。まずは、 ワイドキャラクタ非対応の ANSI 版です。ファイル名は echoback.c としました。
echoback.c#include <stdio.h>
int main(int argc, char* argv[])
{
if(argc >= 2)
{
printf("%s¥n", argv[1]);
}
return 0;
}
簡単ですよね。これをコンパイルします。
コマンドプロンプトC:¥temp>cl.exe -nologo echoback.c echoback.c
コンパイルが成功すると echoback.exe が出来上がります。これに引数 「日本語」 を指定して実行してみます。
コマンドプロンプトC:¥temp>echoback.exe 日本語 日本語
普通に日本語が表示されました。ワイドキャラクタ対応関数を使わなくても日本語を表示することはできます。
ワイドキャラクタ対応版
次にプログラムをワイドキャラクタ対応に書き換えます。
- エントリポイント
main関数をwmain関数に変えます。 - 引数の型を
charからwchar_tに変えます。 printf関数をwprintf関数に変えます。- 文字列リテラル
"%s\n"をL"%ls\n"に変えます。
echoback.c#include <stdio.h>
#include <wchar.h>
int wmain(int argc, wchar_t* argv[])
{
if(argc >= 2)
{
wprintf(L"%ls¥n", argv[1]);
}
return 0;
}
それでは、 コンパイルして実行してみましょう。
コマンドプロンプトC:¥temp>cl.exe -nologo echoback.c echoback.c C:¥temp>echoback.exe 日本語 C:¥temp>
おおっと! 何も表示されずにプロンプトに復帰してしまいました。全然ダメですね。
setlocale
wprintf 関数を正しく動作させるためには setlocale 関数でロケールを指定する必要があります。明示的にロケールを指定することもできますし、 "" (空文字) を指定すればオペレーティングシステムの既定のロケールが設定されます。
#include <locale.h>
setlocale(LC_CTYPE, "");
setlocale をソースコードに追加しましょう。
echoback.c#include <stdio.h>
#include <wchar.h>
#include <locale.h>
int wmain(int argc, wchar_t* argv[])
{
setlocale(LC_CTYPE, "");
if(argc >= 2)
{
wprintf(L"%ls¥n", argv[1]);
}
return 0;
}
もう一度、 コンパイルして実行です。
コマンドプロンプトC:¥temp>cl.exe -nologo echoback.c echoback.c C:¥temp>echoback.exe 日本語 日本語
wprintf 関数で日本語を出力することができましたね。
これで解決! …ではありません。
本当にUnicodeが出力できているか確認する
「日本語」 という文字列を出力しただけでは Unicode の出力を確認したことにはなりません。「日本語」 という文字列は Shift_JIS でも扱うことができますから、 もしかしたら Shift_JIS (≒MS932) が出力されているだけということもありえます。
Unicode 固有の文字を出力できるかどうかを確認しましょう。
Shift_JIS に存在しない文字はたくさんあります。今回は 「剝がす」 を使ってみましょう。Shift_JIS にも含まれる 「剥」 が新字、 Shift_JIS には含まれない 「剝」 が旧字です。
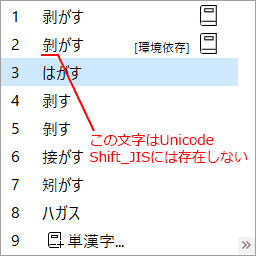
「剝がす」 を出力できれば Shift_JIS の範囲を超えた出力、 すなわち Unicode 出力ができているといえます。
それではさっそく…
コマンドプロンプトC:¥temp>echoback.exe 剝がす がす C:¥temp>echoback.exe 紙を剝がす 紙をがす
なんてこったい /(^o^)\
肝心の 「剝」 という文字だけ欠落しています。
wprintfは文字列をマルチバイトキャラクタに変換して出力する
どうやら wprintf 関数は Shift_JIS (≒MS932) を出力していたようです。
じつは wprintf はワイドキャラクタ (≒Unicode) を直接出力するのではなく、 ロケールに従ってマルチバイトキャラクタに変換して出力をおこなっています。マルチバイトキャラクタへの変換時に存在しない文字が欠落してしまうのです。
setlocale 関数に "" を渡すことでシステム既定のロケールを設定していましたよね? このシステム既定のロケールとはなんなんでしょう?
setlocale 関数は設定したロケールを戻り値として返してくれます。とりあえず、 プログラムで使われているロケールを確認してみましょう。
echoback.c#include <stdio.h>
#include <wchar.h>
#include <locale.h>
int wmain(int argc, wchar_t* argv[])
{
char* locale = setlocale(LC_CTYPE, "");
printf("locale=%s¥n", locale);
if(argc >= 2)
{
wprintf(L"%ls¥n", argv[1]);
}
return 0;
}
setlocale の戻り値を出力するようにしました。コンパイルして実行です。
コマンドプロンプトC:¥temp>cl.exe -nologo echoback.c echoback.c C:¥temp>echoback.exe locale=Japanese_Japan.932
予想通りの結果ですね。システム既定のロケールではコードページ 932 (≒Shift_JIS) が設定されるようです。つまり、 wprintf 関数は Unicode 入力を MS932 に変換してから出力しているということになります。これでは Unicode を出力しているとは言えませんね…。
setlocaleでUTF-8を指定すれば良いのでは?
setlocale 関数に "" を渡すと Shift_JIS になってしまうのであれば、 "" ではなく明示的に UTF-8 を指定すれば良いのではないか? と思いますよね。
試してみましょう。
echoback.c#include <stdio.h>
#include <wchar.h>
#include <locale.h>
int wmain(int argc, wchar_t* argv[])
{
char* locale = setlocale(LC_CTYPE, "ja_JP.UTF-8");
printf("locale=%s¥n", locale);
if(argc >= 2)
{
wprintf(L"%ls¥n", argv[1]);
}
return 0;
}
コンパイルして実行です。
コマンドプロンプトC:¥temp>cl.exe -nologo echoback.c echoback.c C:¥temp>echoback.exe locale=(null)
setlocale の戻り値が NULL になってしまいました。setlocale は無効なロケールを指定すると NULL を返します。つまり、 Windows の C ランタイムは UTF-8 ロケールに対応していないということです。
- 追記
- Windows 10 ビルド 17134 以降のユニバーサル C ランタイムは UTF-8 コードページをサポートしているそうです。
setlocale(LC_ALL, ".UTF8")で UTF-8 に切り替えられます。
_setmode を使ってみる
_setmode は指定したファイルディスクリプタの変換モード (テキストモード/バイナリーモード) を設定する関数です。この関数は拡張されており、 Unicode モードに設定することもできるようになっています。
| 変換モード | 説明 |
|---|---|
| _O_BINARY | 変換せずに出力する。 |
| _O_TEXT | \n を CRLF に変換して出力する。(Windows の場合) |
| _O_U8TEXT | UTF-8 に変換して出力する。 |
| _O_U16TEXT | UTF-16 に変換して出力する。 |
| _O_WTEXT | Unicode に変換して出力する。(UTF-16 との違いは何?) |
標準出力 (stdout) の変換モードを _O_U8TEXT に変更してみましょう。
echoback.c#include <stdio.h>
#include <wchar.h>
#include <io.h>
#include <fcntl.h>
int wmain(int argc, wchar_t* argv[])
{
_setmode(_fileno(stdout), _O_U8TEXT);
if(argc >= 2)
{
wprintf(L"%ls¥n", argv[1]);
}
return 0;
}
コンパイルして実行です。
コマンドプロンプトC:¥temp>cl.exe -nologo echoback.c echoback.c C:¥temp>echoback.exe 剝がす 剝がす
やた! Unicode 出力成功!
_setmode は Windows のコンソールに Unicode を出力する方法の 1 つになりそうですね。
_setmodeの問題点
Unicode の出力に成功した _setmode 関数ですが、 じつは副作用があります。
副作用の 1 つは標準出力をファイルにリダイレクトしたときの文字コードも UTF-8 や UTF-16 になってしまうことです。Unicode 固有の文字を使わないユーザーはリダイレクトで Shift_JIS のファイルになって欲しいと考えるかもしれません。
もう 1 つの副作用は wprintf 関数以外の文字列ストリームも影響を受けてしまうことです。_setmode 関数では標準出力 (stdout) の変換モードを強制的に変更していますから、 wprintf 等のワイドキャラクタ対応関数だけでなく printf 等も影響を受けます。
printf 関数の出力がどうなるのか試してみましょう。
echoback.c#include <stdio.h>
#include <wchar.h>
#include <io.h>
#include <fcntl.h>
int wmain(int argc, wchar_t* argv[])
{
_setmode(_fileno(stdout), _O_U8TEXT);
printf("Hello, World!!¥n");
if(argc >= 2)
{
wprintf(L"%ls¥n", argv[1]);
}
return 0;
}
コンパイルして実行です。
コマンドプロンプトC:¥temp>cl.exe -nologo echoback.c echoback.c C:¥temp>echoback.exe 剝がす 剝がす
Hello, World!! が出力されることを期待していたのですが出ていませんね…。printf 関数も _setmode の影響を受けておかしくなってしまったようです。
printf 等を使わずに wprintf 等のワイドキャラクタ対応関数のみを使うようにできるのであれば、 _setmode は良い解決方法になると思います。ですが、 意外とそれは難しいです。サードパーティー製のライブラリが内部で printf を使っているようなケースで困ることになるでしょう。
wprintf使うのやめようかな…
いろいろと試行錯誤した結果、 私は wprintf 関数を使うのを諦めました。
もう wprintf 使わずに、 WriteFile 関数で標準出力 (STD_OUTPUT_HANDLE) に出力したほうが早いんじゃないかなって。
WriteFile 関数にはテキストモードという概念はなく、 指定されたバイト列を出力していくだけの関数ですから、 自前で文字列をコードページに合わせたバイト列に変換しておく必要があります。でもそれだけです。そんなに難しくなさそうですよね。
材料
GetConsoleOutputCP… コンソールのコードページを取得するWideCharToMultiByte… 文字列を指定したコードページでバイト列に変換するGetStdHandle… 標準出力のハンドルを取得するWriteFile… 指定したハンドルに指定したバイト列を出力する
やってみましょう。
echoback.c#include <Windows.h>
#include <stdlib.h>
#include <stdio.h>
#include <wchar.h>
int wcout(wchar_t* str)
{
HANDLE handle;
UINT code_page;
int mb_size;
char* mb_buf;
DWORD written;
handle = GetStdHandle(STD_OUTPUT_HANDLE);
if(handle == INVALID_HANDLE_VALUE)
{
return -1;
}
code_page = GetConsoleOutputCP();
if(code_page == 0)
{
return -2;
}
mb_size = WideCharToMultiByte(code_page, 0, str, -1, NULL, 0, NULL, NULL);
if(mb_size == 0)
{
return -3;
}
mb_buf = (char*)malloc(mb_size);
if(mb_buf == NULL)
{
return -4;
}
if(WideCharToMultiByte(code_page, 0, str, -1, mb_buf, mb_size, NULL, NULL) == 0)
{
free(mb_buf);
return -5;
}
if(WriteFile(handle, mb_buf, mb_size - 1, &written, NULL) == 0)
{
free(mb_buf);
return -6;
}
free(mb_buf);
return written;
}
int wmain(int argc, wchar_t* argv[])
{
if(argc >= 2)
{
wcout(argv[1]);
wcout(L"¥r¥n");
}
return 0;
}
現在のコードページに合わせて出力をおこなう wcout 関数を作ってみました。少し長いコードですが、 やってることはそんなに難しくないです。
それではコンパイルして実行してみましょう。
コマンドプロンプトC:¥temp>cl.exe -nologo echoback.c echoback.c C:¥temp>echoback.exe 剝がす ?がす
「剝」 の文字が 「?」 に文字化けしてしまいましたが、 これは想定の範囲内です。現在のコードページが MS932 (≒Shift_JIS) になっていますからね。
コマンドプロンプトC:¥temp>chcp 現在のコード ページ: 932
コードページを UTF-8 に変更して、 もう一度、 実行してみましょう。(コードページを UTF-8 に変更するには chcp 65001 を実行します。)
コマンドプロンプトC:¥temp>chcp 65001 Active code page: 65001 C:¥temp>echoback.exe 剝がす 剝がす
できました!
この仕組みであれば Unicode 固有の文字を必要としないユーザーはコードページ 932 のまま使用することができ、 その場合はファイルリダイレクトの結果も MS932 (≒Shift_JIS) になってくれます。
Unicode 固有の文字を使う必要があるユーザーはコードページ 65001 (UTF-8) に切り替えれば済みます。
もちろん、 printf 等の関数と共存することもできます。
自作の wcout 関数には改行文字の変換機能がないことに注意してください。"\n" は CRLF ではなく LF のみを出力します。CRLF を出力するには "\r\n" を指定する必要があります。("\n" だけでもコンソールの表示は問題ありませんが、 ファイルにリダイレクトしたときに LF のみになってしまいます。)
WindowsでUTF-8が使えるようになる日も近い?
Windows 10 もメモ帳の既定の文字コードが ANSI から UTF-8 に変更されたりと次第に Unicode ネイティブに近づいている感じがします。
Windows 10 1803 からはロケールを UTF-8 にできるベータ機能も追加されています。
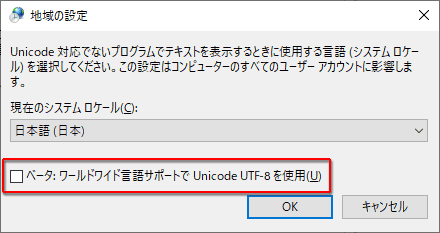
このようにシステムロケールを UTF-8 に切り替える機能が追加されていたので setlocale 関数でも UTF-8 が指定できるようになったのではないかと期待したのですが、 まだダメでした。「ベータ」 が外れたあかつきには setlocale でも UTF-8 が指定できるようになってくれるといいのですが…。
- 追記
setlocaleで UTF-8 に切り替えられないのは私が古い C ランタイム (msvcrt.dll) を使っていたからでした。Windows 10 ビルド 17134 以降のユニバーサル C ランタイムは UTF-8 コードページをサポートしているそうです。
前述の自作 wcout 関数はコードページに応じて出力が変わるので、 将来、 Windows のシステムロケールが UTF-8 に変更されても、 そのまま問題なく動作するはずです。
Windows のコンソールアプリケーションで Unicode を出力する手順は以上です。












